Welcome back to Showa-retro real dungeon!
1-1-12 Asakusa, Taitō Ward, Tokyo, Japan
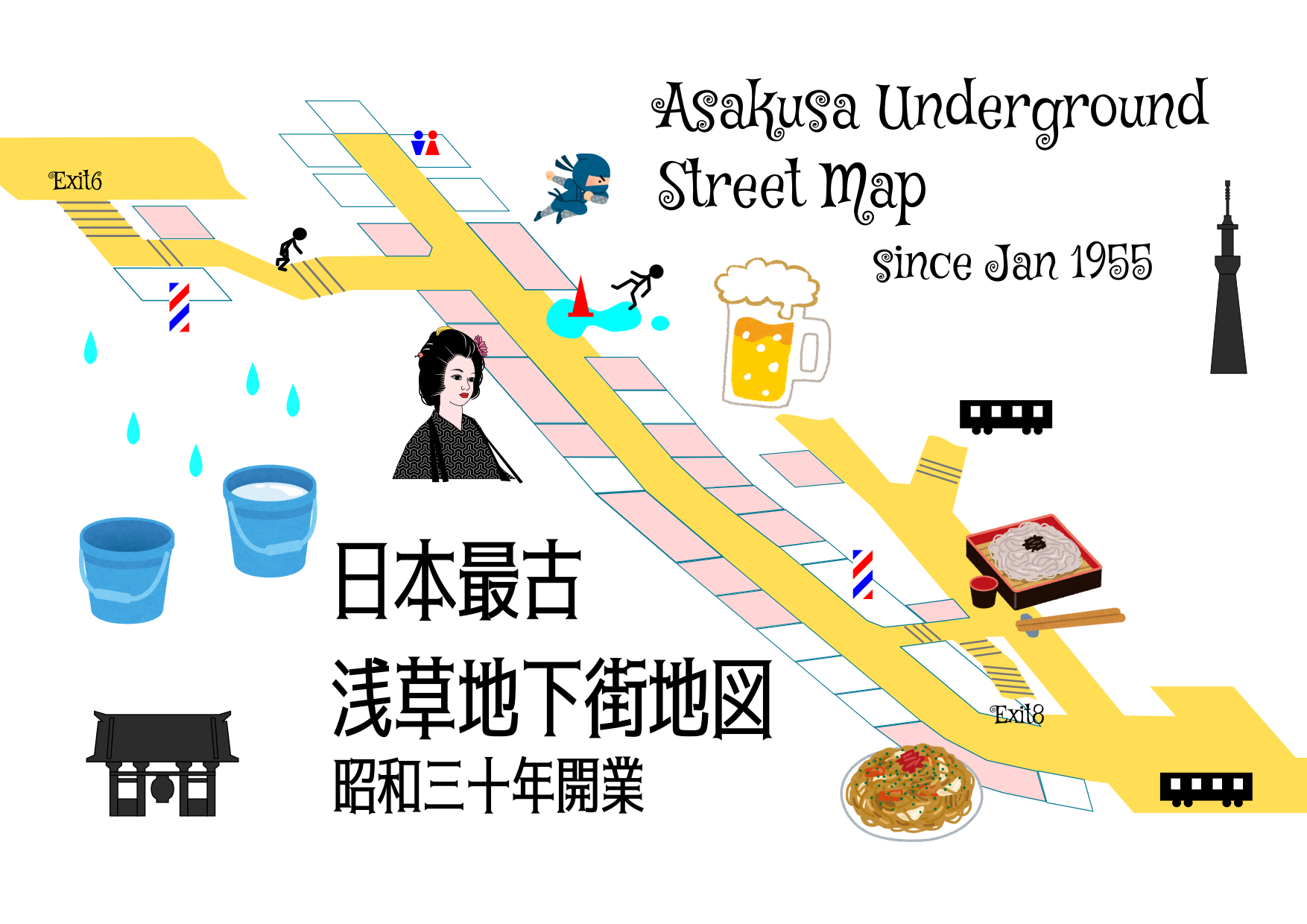
The Asakusa Underground Street is a must-visit retro wonderland—intriguing, nostalgic, and incredibly photogenic. Construction began beneath Umamichi Street in February 1954, and when it opened on 28 January 1955, it served as a clever subterranean shortcut connecting the Tokyo Metro Ginza Line‘s Asakusa Station to Sensō-ji Temple via Shin-Nakamise (Shinnaka) Arcade.
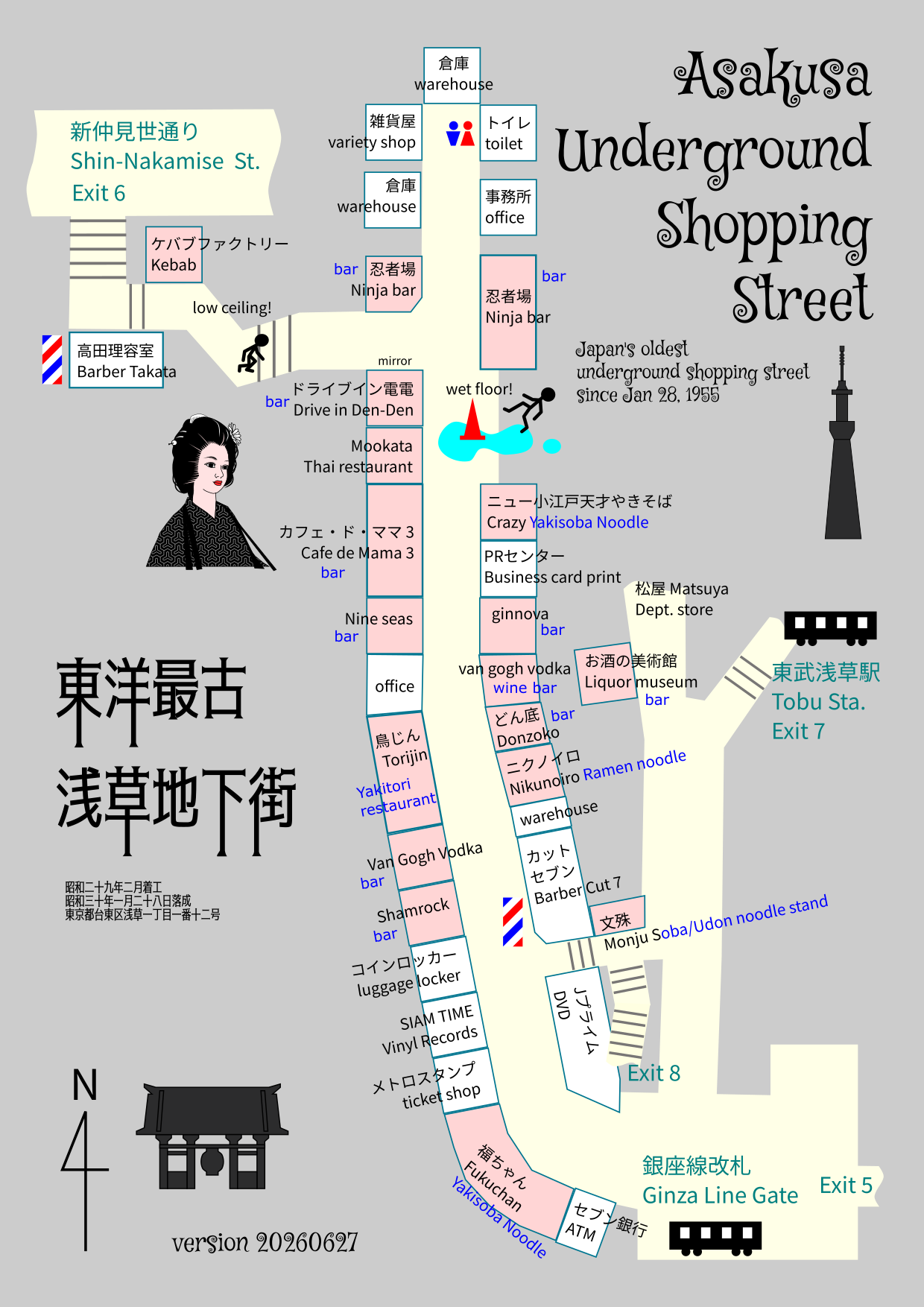
Laid out with 4-meter-wide walkways, it is hosting around 20 shops nestled into compact 4×4-meter plots.
Shops












The passages feel cozy, filled with the smoky aroma of sizzling yakisoba, where you’ll need to watch out for dripping pipes and low ceilings.
It’s not a crafted theme park attraction. Historically, Japan’s very first underground shopping street was the Kanda Sudamachi Subway Store, opening in 1929. Later, during the post-war era, the Ginza Miharabashi Underground Street was completed almost simultaneously with the one in Asakusa. However, because the Kanda and Ginza locations have since closed due to earthquake safety concerns, Asakusa stands alone today as Japan’s oldest surviving underground shopping street.
Both Exits 8 and Exit 6 are absurdly narrow and inconvenient. Yet, despite being positioned right at the bustling crossroads of three major train lines—the Tokyo Metro Ginza Line, Tobu Skytree Line, and Toei Asakusa Line—this space still clings tightly to its Showa-retro vibe, existing even today like a world apart.












- Barber Takata
- Kebab Factory
- Drive-In DenDen (instagram)
- Thai Restaurant Mookata (instagram)(twitter)
- Cafe de Mama 3
- nine seas bar
- Torijin Yakitori
- Van Gogh Vodka
- Van Gogh Vodka Wine
- Shamrock bar
- Siam Time Vinyl Records
- Fukuchan Yakisoba, Motsuni, Gyusuji
- J Price Used DVD etc
- Barber Cut Seven
- Nikunoiro (twitter) Ramen, Donburi
- Donzoko bar
- ginnova bar
- PR Center business card print
- Crazy Yakisoba New Koedo (instagram) (youtube)
- Ninja Bar (youtube) (instagram) (twitter)
- Liquor Museum bar
- Monju Noodle Stand
- Metro Stamp ticket shop
The following might prove to be valuable advice to help you avoid wasting time in Asakusa underground dungeon.
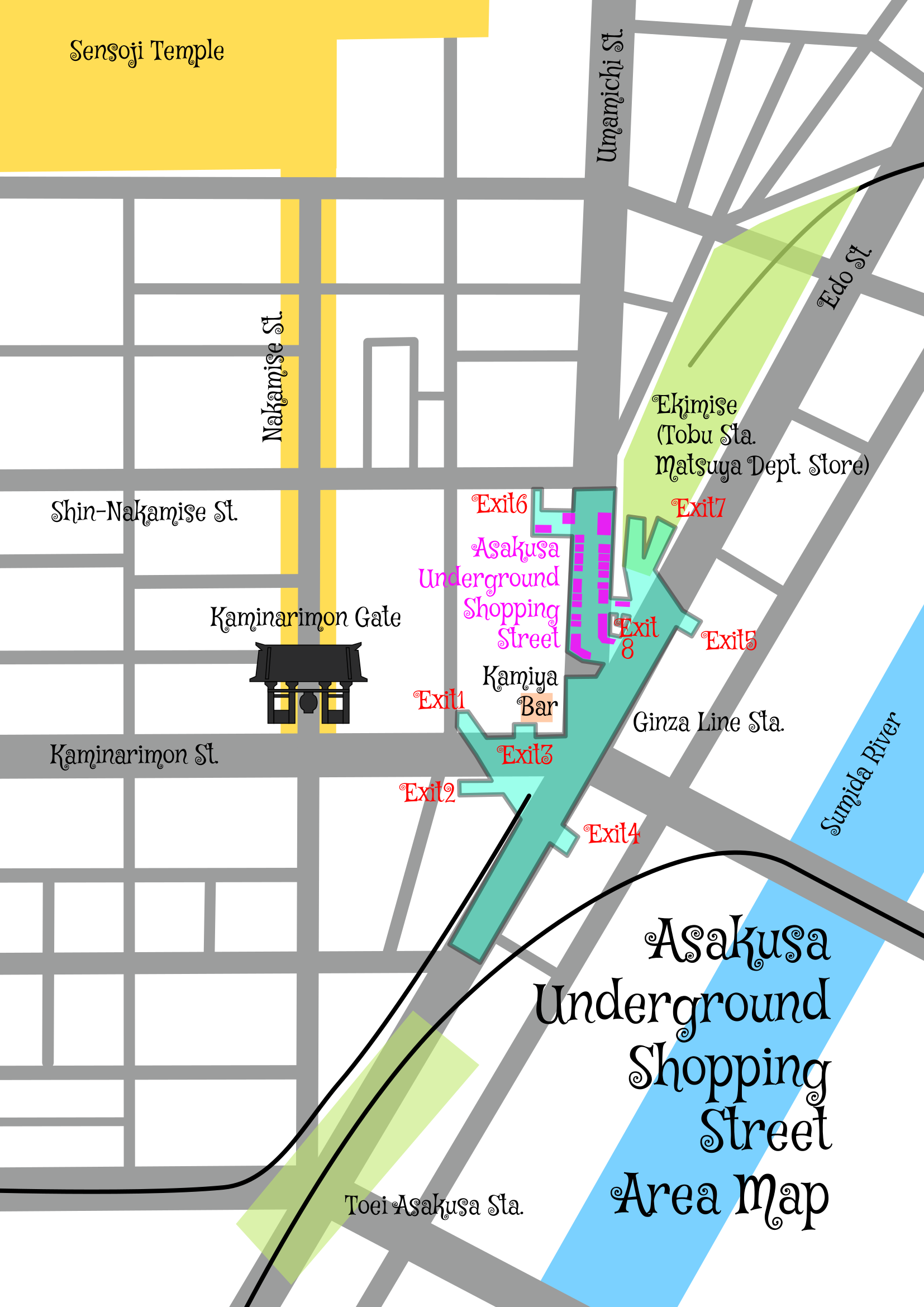
If you are coming from the direction of Senso-ji Temple, enter the underground shopping arcade via Exit 6, which faces Shin-Nakamise Street; passing through the arcade leads directly to the Ginza Line. Conversely, if you exit the ticket gate at the front of the arriving Ginza Line train and turn immediately left, you can enter the arcade. While Exit 6 offers the most convenient, direct route between Senso-ji and the Ginza Line, it is narrow, has a low ceiling, and features a floor that is slippery due to water leakage. Furthermore, the shutters are closed from late at night until 6:00 AM—or sometimes the shutter is closed just before the ticket gate—meaning Exit 6 cannot be used when taking the first train at 5:00 AM.
If you arrive at Asakusa via the Tobu Line, you can enter the underground shopping arcade along the way by heading toward the Ginza Line.
If you arrive via the Toei Asakusa Line, the easiest approach might simply be to go up to street level and head for Exit 8. However, Exit 8 requires crossing at the intersection of Umamichi-dori, Kaminarimon-dori, and Edo-dori, which involves a time-consuming wait for traffic lights; personally, I do not use this route (Back when this underground mall was built —an era when there was far less vehicular traffic than there is now—Exit 8 was likely a more convenient entrance).
You cannot enter the underground shopping arcade from Exits 1 or 3 (unless you pass through the Ginza Line ticket gates). In short, the only ways to enter the arcade are via Exit 6 or from the Ginza Line (though it is technically possible—albeit a bit of a detour—to arrive via Exits 8, 7, or 5).
One could argue that the issues with the Asakusa Underground Shopping Street stem from the overall design of Asakusa Station (though that very complexity is part of the “Asakusa Dungeon’s” unique charm—setting aside, for the moment, the fact that the Tsukuba Express Asakusa Station is too far away for a convenient transfer).
While the Tokyo Metro website does list Exits 6, 7, and 8 on the Ginza Line Asakusa Station map, the layout is extremely confusing (with the route from the underground shopping street to Exit 6, in particular, being heavily simplified). Exits A4 and A5 were likely originally designated as exits for the Toei Asakusa Line. Connections between the Toei Line and the Ginza Line are notoriously poor; while transferring to the Toei Line is relatively smooth if you arrive at Platform 1, arriving at Platform 2 makes the process a hassle—so much so that in-train announcements sometimes suggest getting off one stop early at Tawaramachi Station and waiting for the next train arriving at Platform 1. That said, arriving at Platform 2 is actually more convenient if you are heading toward Kaminarimon or Senso-ji Temple. If you intend to use Exits 6, 7, or 8, it is best to ride in the frontmost car. There is no direct connection between the Toei Line and the Tobu Line (there is no underground passageway linking the two that bypasses the Ginza Line). Nor is there a connecting walkway between the exits, so one has no choice but to go up to street level. Even if there were a connecting walkway, it would likely twist and turn endlessly, forcing you to trudge up and down stairs. All who enter Asakusa Station must abandon all hope. To get to the Toei Asakusa Line from Senso-ji Temple or the Tobu station area, your best bet is to ignore all the Ginza Line exits and enter through the dedicated Toei entrance. The design is so outdated and haphazard that it might be better to simply redevelop the whole thing—much like Shinjuku or Shibuya—but doing so would strip Asakusa Station of its unique character. Perhaps, then, it should be designated a “Showa-era heritage site” and preserved exactly as it is for all eternity.
Exits 6 and 8 are barely two meters wide—far too narrow to serve effectively as a shortcut from the Ginza Line to Shin-Nakamise-dori (reminiscent, perhaps, of the “shortcut (抜けられます, literary, you can go directly to the station via this passage)” signs found in the old Tamanoi (玉の井) district (the area on the east side of the Sumida River); a product of the penny-pinching mentality that prevailed in the immediate postwar era of the mid-1950s). These two exits are the reason why, despite their location at a key junction in Asakusa, they function as little more than dead-end spurs. When heading above ground from the Ginza Line, one would typically use Exits 1, 2, 3, or 7; Exits 4 and 5 open out toward the Sumida River, so they are rarely used.
The passageways in the underground mall are only four meters wide, and to make matters worse, tables and merchandise displays spill out from the shops. Water leakage is visible throughout the entire complex, and the situation is completely beyond repair. Air conditioning was finally installed only in the summer of 2025.





